[华为] Bye,英伟达!华为NPU,跑出准万亿参数大模型
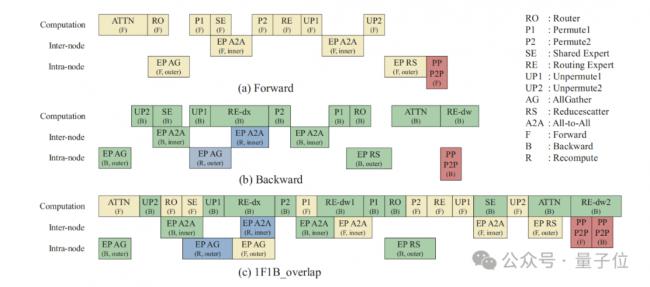
因此,团队采用基于VPP调度的自适应前反向掩盖策略,实现如下图流程的前向计算掩盖反向通信,反向计算掩盖前向通信。
核心设计包括:利用机间与机内通信链路带宽独立特点实现机内通信与机间通信的互相掩盖,利用算子的有效排布缓解host bound,将专家反向dw计算与dx计算分离做更细粒度的掩盖。
对显存进行优化时,团队采用了新的计算方式。
不再使用传统的全重计算,而是对细粒度模块,像MLA、Permute和激活函数进行重新计算,这样能避免额外的计算消耗。
同时,运用Tensor Swapping技术,把重新计算不太划算的激活值,先转移到CPU那边,等需要反向计算时再提前取回来,让NPU内存得到更高效的利用。
团队还在研究新的显存节省方法,准备把多种优化策略组合起来,根据不同的设备配置,找到最适合的组合,既能提高显存利用率,又不会降低模型性能。
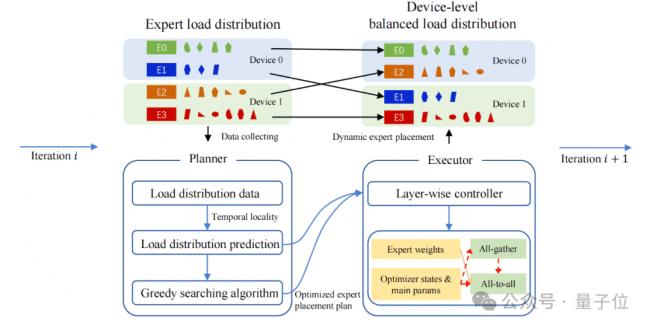
让每台设备上专家处理的任务量(token 数量)尽量均匀,能大幅提升训练效率。
为此,团队设计了一套动态的设备级负载均衡机制。
首先,规划器就像一个“小管家”,通过观察一段时间内专家的工作负载情况,预测未来的任务量,再用贪心算法规划出如何重新分配专家,让设备间的任务更均衡。
然后,执行器定期行动,把不同Transformer层的专家参数和优化器状态在设备间转移。通过这种动态调整,模型的MFU提高了10%。
除了上面这些,团队还开发了一些专门适配昇腾设备的技术,包括主机端优化、计算卸载与数据共享,以及融合算子。
算子下发优化:为了解决host端性能瓶颈问题,团队减少了那些需要频繁同步操作的算子,避免不必要的等待。同时,使用细粒度CPU绑核技术,让CPU和NPU配合得更好,任务下发更顺畅。
计算卸载与数据共享:当遇到NPU处理起来效率低的数据计算,或者在TP区域内数据传输慢的情况,作者把这些不适合NPU的计算从主计算流程中分离出来,交给CPU在数据加载时处理。再结合数据共享技术,让同一节点内的计算和数据传输速度都大大提高。
融合算子:除了盘古稠密模型里已有的FlashAttention 和 RMSNorm融合算子,团队在MoE模型里又加入了 GMMAdd、Permute和Umpermute融合算子。GMMAdd融合算子把GroupedMatMul的反向计算和梯度累加放在一起处理,利用并行和流水线技术减少调度时间。Permute和Unpermute融合算子整合了多种操作,能更快地读写内存。
算子下发优化:为了解决host端性能瓶颈问题,团队减少了那些需要频繁同步操作的算子,避免不必要的等待。同时,使用细粒度CPU绑核技术,让CPU和NPU配合得更好,任务下发更顺畅。
 您的点赞是对我们的鼓励
您的点赞是对我们的鼓励
 这条新闻还没有人评论喔,等着您的高见呢
这条新闻还没有人评论喔,等着您的高见呢
核心设计包括:利用机间与机内通信链路带宽独立特点实现机内通信与机间通信的互相掩盖,利用算子的有效排布缓解host bound,将专家反向dw计算与dx计算分离做更细粒度的掩盖。

对显存进行优化时,团队采用了新的计算方式。
不再使用传统的全重计算,而是对细粒度模块,像MLA、Permute和激活函数进行重新计算,这样能避免额外的计算消耗。
同时,运用Tensor Swapping技术,把重新计算不太划算的激活值,先转移到CPU那边,等需要反向计算时再提前取回来,让NPU内存得到更高效的利用。
团队还在研究新的显存节省方法,准备把多种优化策略组合起来,根据不同的设备配置,找到最适合的组合,既能提高显存利用率,又不会降低模型性能。
让每台设备上专家处理的任务量(token 数量)尽量均匀,能大幅提升训练效率。
为此,团队设计了一套动态的设备级负载均衡机制。

首先,规划器就像一个“小管家”,通过观察一段时间内专家的工作负载情况,预测未来的任务量,再用贪心算法规划出如何重新分配专家,让设备间的任务更均衡。
然后,执行器定期行动,把不同Transformer层的专家参数和优化器状态在设备间转移。通过这种动态调整,模型的MFU提高了10%。

除了上面这些,团队还开发了一些专门适配昇腾设备的技术,包括主机端优化、计算卸载与数据共享,以及融合算子。
算子下发优化:为了解决host端性能瓶颈问题,团队减少了那些需要频繁同步操作的算子,避免不必要的等待。同时,使用细粒度CPU绑核技术,让CPU和NPU配合得更好,任务下发更顺畅。
计算卸载与数据共享:当遇到NPU处理起来效率低的数据计算,或者在TP区域内数据传输慢的情况,作者把这些不适合NPU的计算从主计算流程中分离出来,交给CPU在数据加载时处理。再结合数据共享技术,让同一节点内的计算和数据传输速度都大大提高。
融合算子:除了盘古稠密模型里已有的FlashAttention 和 RMSNorm融合算子,团队在MoE模型里又加入了 GMMAdd、Permute和Umpermute融合算子。GMMAdd融合算子把GroupedMatMul的反向计算和梯度累加放在一起处理,利用并行和流水线技术减少调度时间。Permute和Unpermute融合算子整合了多种操作,能更快地读写内存。
算子下发优化:为了解决host端性能瓶颈问题,团队减少了那些需要频繁同步操作的算子,避免不必要的等待。同时,使用细粒度CPU绑核技术,让CPU和NPU配合得更好,任务下发更顺畅。
| 分享: |
| 注: | 在此页中阅读全文 |

