[华为] Bye,英伟达!华为NPU,跑出准万亿参数大模型
团队首先在一个20B的先导MoE上对比了不同专家总数下drop-and-pad和dropless的性能:
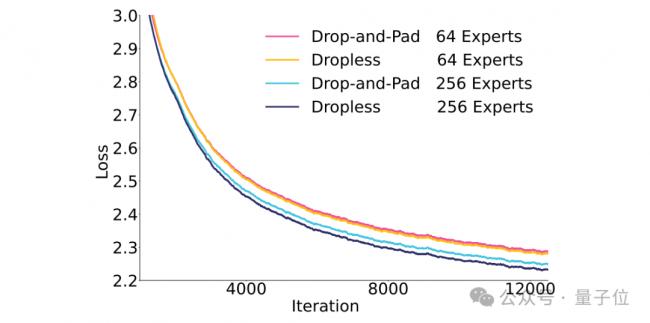
结果显示,dropless总是优于drop-and-pad方案。
并且这种性能的差距会随着专家数变多、模型参数变大而进一步放大。
因此在训练盘古Ultra MoE时采用了dropless的方案,并重点优化了这一策略下的训练效率。
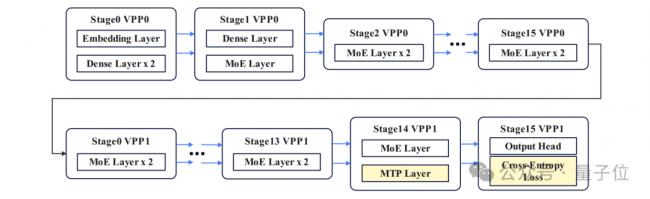
具体而言,团队从四个关键方向对盘古Ultra MoE 模型进行了全面优化,包括改进并行计算策略、优化数据传输效率、提升显存使用效果,以及让任务分配更均匀。
在由6000+个昇腾NPU组成的大型计算集群上,模型的算力利用率(MFU,即Model FLOPs Utilization)达到了30.0%,和优化前相比,提升幅度高达58.7%。
团队用一套能模拟全流程的模型仿真系统,反复试验寻找最佳的并行计算方案。
最终确定的方案是:采用16路流水线并行、8路张量并行、4路专家并行、2路虚拟流水线并行,以及48路数据并行。
在专家并行这块,团队用了TP拓展EP的策略。
简单来说,就是让TP组来划分专家数量,这样做能避免因为TP组拆分专家参数,导致GMM算子在处理小规模专家数据时效率暴跌的问题。
整个系统里,专家组总数是32组(TP 和 EP 组合计算得出),一共划分成256个专家。
虚拟流水线并行策略效果特别好,以前训练时,计算资源闲置(空泡率)的情况占18.98%,用了新策略后,直接降到10.49% 。
同时,通过合理分配MTP层和损失函数层的任务,把任务分配不均衡导致的负载溢出,控制在5%以内,大大减少了任务分配不均带来的负面影响。
为了解决并行扩展中的通信瓶颈,团队还设计了两个主要技术。
首先就是Hierarchical EP Communication分级EP通信。
相比机内通信,跨机通信带宽较低。团队采用分级EP通信,减少跨机通信量。
具体来说,采用跨机Allgather 通信将所有tokens同步到机内,然后在机内对token排序并采用机内AlltoAll通信对tokens重新分配。
机内通信和机间通信都可以通过前反向通信掩盖技术掩盖,从下图的通信量对比可以看到分级EP通信对跨机通信量减少的效果。
其次是Adaptive Pipe Overlap Mechanism自适应前反向掩盖策略。
即使采用分级EP通信策略,EP通信的耗时占比仍然很高。前反向的大部分EP通信与计算均具有依赖关系,自然掩盖策略会暴露大部分EP通信。
如果采用通算融合算子等自掩盖策略,又不可避免地会降低计算效率。
 不错的新闻,我要点赞
不错的新闻,我要点赞
 无评论不新闻,发表一下您的意见吧
无评论不新闻,发表一下您的意见吧

结果显示,dropless总是优于drop-and-pad方案。
并且这种性能的差距会随着专家数变多、模型参数变大而进一步放大。
因此在训练盘古Ultra MoE时采用了dropless的方案,并重点优化了这一策略下的训练效率。
具体而言,团队从四个关键方向对盘古Ultra MoE 模型进行了全面优化,包括改进并行计算策略、优化数据传输效率、提升显存使用效果,以及让任务分配更均匀。
在由6000+个昇腾NPU组成的大型计算集群上,模型的算力利用率(MFU,即Model FLOPs Utilization)达到了30.0%,和优化前相比,提升幅度高达58.7%。
团队用一套能模拟全流程的模型仿真系统,反复试验寻找最佳的并行计算方案。
最终确定的方案是:采用16路流水线并行、8路张量并行、4路专家并行、2路虚拟流水线并行,以及48路数据并行。
在专家并行这块,团队用了TP拓展EP的策略。
简单来说,就是让TP组来划分专家数量,这样做能避免因为TP组拆分专家参数,导致GMM算子在处理小规模专家数据时效率暴跌的问题。
整个系统里,专家组总数是32组(TP 和 EP 组合计算得出),一共划分成256个专家。

虚拟流水线并行策略效果特别好,以前训练时,计算资源闲置(空泡率)的情况占18.98%,用了新策略后,直接降到10.49% 。
同时,通过合理分配MTP层和损失函数层的任务,把任务分配不均衡导致的负载溢出,控制在5%以内,大大减少了任务分配不均带来的负面影响。

为了解决并行扩展中的通信瓶颈,团队还设计了两个主要技术。
首先就是Hierarchical EP Communication分级EP通信。
相比机内通信,跨机通信带宽较低。团队采用分级EP通信,减少跨机通信量。
具体来说,采用跨机Allgather 通信将所有tokens同步到机内,然后在机内对token排序并采用机内AlltoAll通信对tokens重新分配。
机内通信和机间通信都可以通过前反向通信掩盖技术掩盖,从下图的通信量对比可以看到分级EP通信对跨机通信量减少的效果。
其次是Adaptive Pipe Overlap Mechanism自适应前反向掩盖策略。
即使采用分级EP通信策略,EP通信的耗时占比仍然很高。前反向的大部分EP通信与计算均具有依赖关系,自然掩盖策略会暴露大部分EP通信。
如果采用通算融合算子等自掩盖策略,又不可避免地会降低计算效率。
| 分享: |
| 注: | 在此页中阅读全文 |

