[华为] Bye,英伟达!华为NPU,跑出准万亿参数大模型
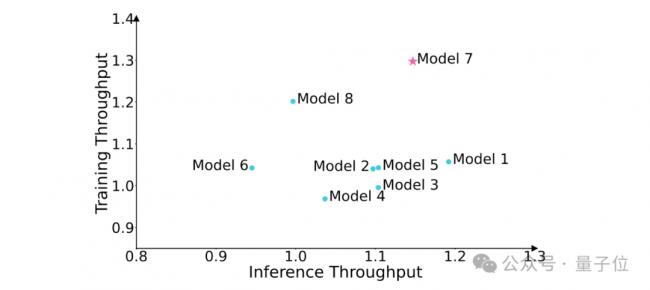
在模型结构仿真方面,团队根据硬件的适配特点,对模型参数的选择范围进行了大幅调整,把原本庞大的参数搜索空间缩小到了10000个左右。
为了能更准确地知道不同模型的性能极限,团队开发了一套专门的建模仿真工具。这个工具很厉害,它把模型结构、运行时采用的策略,还有硬件系统,都拆分成了一个个小的参数。
通过对算子、Block、Layer这些层级的计算、数据传输和读取操作进行模拟,就能算出模型从头到尾的整体性能。经过和实际测试数据对比,发现这个仿真工具的准确率能达到85%以上。
团队用这个建模仿真工具,把所有符合硬件适配要求的参数组合都测试了一遍,仔细评估它们在训练和推理时的数据处理速度,最后找到了性能相对更好的模型结构,具体情况可以看下面的图。
接下来,我们再看下MoE训练的分析。
在训练MoE模型的时候,和普通的稠密模型相比,有个特别让人头疼的问题,就是负载不均衡。
打个比方,就像一群人干活,有的人忙得不可开交,有的人却闲着没事干,这样效率肯定高不了。
为了解决这个问题,科研界从算法角度想了很多办法,提出了各种各样的辅助损失函数,这些函数关注的均衡范围不太一样。
比如,早期有专门针对序列级别的均衡辅助损失,还有通义千问提出的DP - Group(也就是全局批次大小)均衡辅助损失。
这些辅助损失函数,就像是给MoE模型里的路由模块(负责分配任务的部分)定了规矩,通过不同程度的约束,让它把任务分配得更均匀一些。具体的约束情况,都整理在下面的表格里了。
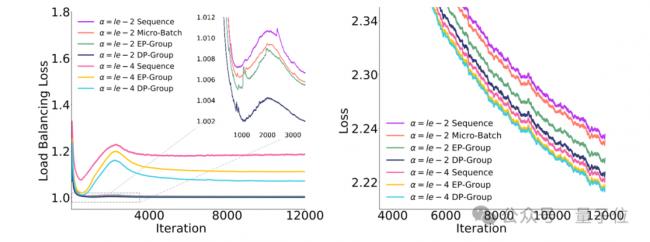
团队还研发出了一种全新的EP组负载均衡损失算法。
和传统的micro-batch辅助损失相比,它不会过度强求局部任务分配的绝对均衡,避免了“矫枉过正”;跟DP组的均衡损失比起来,它在数据传输时耗费的资源更少,能节省不少通信成本。
而且在对专家任务量的约束程度上,它处于两者之间,是个更折中的方案。
为了验证这个新算法的效果,团队在一个总参数量达200亿(20B)的先导MoE模型上,专门做了消融实验,具体情况如下:
为了应对专家负载不均的“木桶效应”,MoE可以采用drop-and-pad的方式来提升训练的吞吐。
 觉得新闻不错,请点个赞吧
觉得新闻不错,请点个赞吧
 无评论不新闻,发表一下您的意见吧
无评论不新闻,发表一下您的意见吧
为了能更准确地知道不同模型的性能极限,团队开发了一套专门的建模仿真工具。这个工具很厉害,它把模型结构、运行时采用的策略,还有硬件系统,都拆分成了一个个小的参数。
通过对算子、Block、Layer这些层级的计算、数据传输和读取操作进行模拟,就能算出模型从头到尾的整体性能。经过和实际测试数据对比,发现这个仿真工具的准确率能达到85%以上。
团队用这个建模仿真工具,把所有符合硬件适配要求的参数组合都测试了一遍,仔细评估它们在训练和推理时的数据处理速度,最后找到了性能相对更好的模型结构,具体情况可以看下面的图。

接下来,我们再看下MoE训练的分析。
在训练MoE模型的时候,和普通的稠密模型相比,有个特别让人头疼的问题,就是负载不均衡。
打个比方,就像一群人干活,有的人忙得不可开交,有的人却闲着没事干,这样效率肯定高不了。
为了解决这个问题,科研界从算法角度想了很多办法,提出了各种各样的辅助损失函数,这些函数关注的均衡范围不太一样。

比如,早期有专门针对序列级别的均衡辅助损失,还有通义千问提出的DP - Group(也就是全局批次大小)均衡辅助损失。
这些辅助损失函数,就像是给MoE模型里的路由模块(负责分配任务的部分)定了规矩,通过不同程度的约束,让它把任务分配得更均匀一些。具体的约束情况,都整理在下面的表格里了。
团队还研发出了一种全新的EP组负载均衡损失算法。
和传统的micro-batch辅助损失相比,它不会过度强求局部任务分配的绝对均衡,避免了“矫枉过正”;跟DP组的均衡损失比起来,它在数据传输时耗费的资源更少,能节省不少通信成本。
而且在对专家任务量的约束程度上,它处于两者之间,是个更折中的方案。
为了验证这个新算法的效果,团队在一个总参数量达200亿(20B)的先导MoE模型上,专门做了消融实验,具体情况如下:

为了应对专家负载不均的“木桶效应”,MoE可以采用drop-and-pad的方式来提升训练的吞吐。
| 分享: |
| 注: | 在此页中阅读全文 |

