-
_NEWSDATE: 2025-02-06 | News by: 科普中国 | 有0人参与评论 | _FONTSIZE: _FONT_SMALL _FONT_MEDIUM _FONT_LARGE近日,中国“深度求索”公司发布的具备深度思考和推理能力的开源大模型 DeepSeek-R1 受到了全世界的关注。
在 DeepSeek-R1 之前,美国 OpenAI 公司的 GPT-o1,Athropic 公司的 Claude,Google 公司的 Gemini,都号称具备了深度思考和推理能力。这些模型在专业人士和吃瓜网友的五花八门的测试中,表现的确是惊才绝艳。
特别引起我们兴趣的,是 Google 的专用模型 AlphaGeometry 在公认高难度的国际奥林匹克数学竞赛中取得了 28/42 的成绩,获得银牌。学生时代我们也接触过奥数,深知能在此类国际奥赛中获银牌的选手,无一不是从小就体现出相当数学天赋,且一路努力训练的高手。能够达到这个水平的 AI,称其为具备了强大的思考能力并不过分。自打那之后,我们就一直好奇,这些强大的 AI,它们的物理水平又如何?
1 月 17 日,中科院物理所在江苏省溧阳市举办了“天目杯”理论物理竞赛。没过两天, DeepSeek-R1 的发布引爆 AI 圈,它自然成了我们测试的首选模型。此外我们测试的模型还包括:OpenAI 发布的 GPT-o1,Anthropic 发布的 Claude-sonnet。
下面是我们测试的方式:
1.整个测试由 8 段对话完成。
2.第一段对话的问题是“开场白”:交代需要完成的任务,问题的格式,提交答案的格式等。通过 AI 的回复人工确认其理解。
3.依次发送全部 7 道题目的题干,在收到回复后发送下一道题,中间无人工反馈意见。
4.每道题目的题干由文字描述和图片描述两部分组成(第三、五、七题无图)。
5.图片描述是纯文本方式,描述的文本全部生成自 GPT-4o,经人工校对。
6.每个大模型所拿到的文字材料是完全相同的(见附件)。
上述过程后,对于每个大模型我们获得了 7 段 tex 文本,对应于 7 道问题的解答。以下是我们采取的阅卷方式:
1.人工调整 tex 文本至可以用 Overleaf 工具编译,收集编译出的 PDF 文件作为答卷。
2.将 4 个模型的 7 道问题的解答分别发送给 7 位阅卷人组成的阅卷组。
3.阅卷组与“天目杯”竞赛的阅卷组完全相同,且每位阅卷人负责的题目也相同。举例:阅卷人 A 负责所有人类和 AI 答卷中的第一题;阅卷人 B 负责所有人类和 AI 答卷中的第二题,等等。
4.阅卷组汇总所有题目得分。
结果如何呢?请看下表。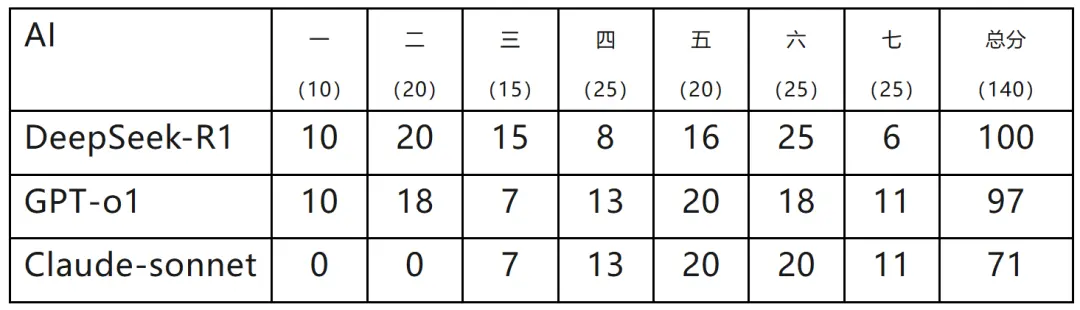
结果点评:
1.DeepSeek-R1 表现最好。基础题(前三题分数拿满),第六题还得到了人类选手中未见到的满分,第七题得分较低似乎是因为未能理解题干中“证明”的含义,仅仅重述了待证明的结论,无法得分。查看其思考过程,是存在可以给过程分的步骤的,但最后的答案中这些步骤都没有体现。
- 新闻来源于其它媒体,内容不代表本站立场!
- 摆脱辉达?传DeepSeek R2全部用华为芯片
- DeepSeek应用存两大风险 微软禁员工使用
- 5月11日追剧日历,8部电视剧有更新,古装剧《淮水竹亭》点映收官
- 温哥华牙医 采用先进技术最新设备
-
- 惨烈 加国两车相撞5死BC男子重伤
- 新内阁将很精简 超过一半是新面孔
- 老父亲在大温住院 莫名摔成了骨折
- 什么鬼?大温推行成人如厕训练活动
- 又是超速 大温两车相撞一辆底朝天
- 西海岸炼油厂出问题 大温油价上涨
-
- 绝大多数加国人宁愿在本国公路旅行,也不愿前往美国
- 盖茨拟捐几乎全部身家 斥马斯克杀最贫穷儿童
- 魔鬼藏在细节中,日内瓦协议中共自取其辱
- 能干扰F-22的"阵风"战机 为何逃不过中国导弹
- 小马哥和小泽在雨中相拥,不愿分开
- 中国忧心"2下场"!选择对美让步(图
-
- 温哥华牙医诊所 经验丰富服务全面
- 内幕:习误判惨遭重击 终给川普递上诚意清单
- 传白宫致函中共 对北京提出四项要求
- 中国"仍然占上风" 语气相当强硬
- 纪念苏联伟大卫国战争胜利80周年,纪念的是什么?
- 王兴兴最新发声:我们非常缺人,所有岗位都缺!
-
目前还没有人发表评论, 大家都在期待您的高见
