-
日期: 2025-02-03 | 来源: 爱范儿 | 有0人参与评论 | 字体: 小 中 大
需要说明的是,DeepSeek 的独特之处在于他们率先实现了这种成本和性能水平。
虽然 Mistral 和 Llama 模型也曾在开源模型上做过类似的事情,但 DeepSeek 做到的程度独树一帜。如果到了年底,成本再下降 5 倍,也请不要感到惊讶。
R1 凭什么迅速追上 OpenAI o1大家热议的另一个话题,是 R1 能够达到与 o1 相当的效果,而 o1 仅在 9 月发布。
仅仅几个月时间,DeepSeek 是如何如此迅速地赶上的呢?
问题的关键在于,推理能力形成了一种全新的范式。
推理范式迭代速度更快,且以较少的计算资源即可获得显著收益。正如我们在扩展定律报告中提到的,以往的范式依赖于预训练,而这种方式不仅成本越来越高,且已经难以取得稳健的进步。
新的推理范式,专注于通过合成数据生成和在现有模型上进行后训练中的强化学习来提升推理能力,从而以更低的成本实现更快的进步。
较低的入门门槛加上易于优化,使得 DeepSeek 能够比过去更快地复制 o1 方法。随着各方探索如何在这一新范式下进一步扩展,我们预计不同模型在匹配性能的时间差距将会拉大。
需要注意的是,R1 论文中没有提及所使用的计算资源。这绝非偶然 —— 为了生成用于后训练的合成数据,R1 需要大量的计算资源,更不用说强化学习了。
R1 是一款非常优秀的模型,但它披露的一些基准测试也具有误导性。R1 特意没有提及那些它并不领先的基准测试,虽然在推理性能上 R1 与 o1 不相上下,但在每项指标上它并不都是明显的赢家,在许多情况下甚至不如 o1。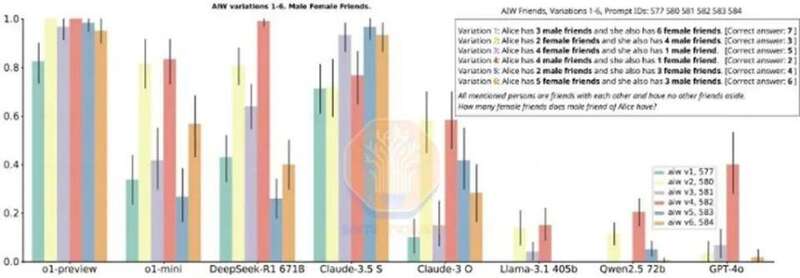
这里我们还没有提到 o3。o3 的能力明显高于 R1 和 o1。实际上,OpenAI 最近分享了 o3 的结果(还提前发布了 o3-mini ),其基准测试的扩展呈垂直趋势。
这似乎再次证明了「深度学习遭遇瓶颈」,但这个瓶颈不同以往。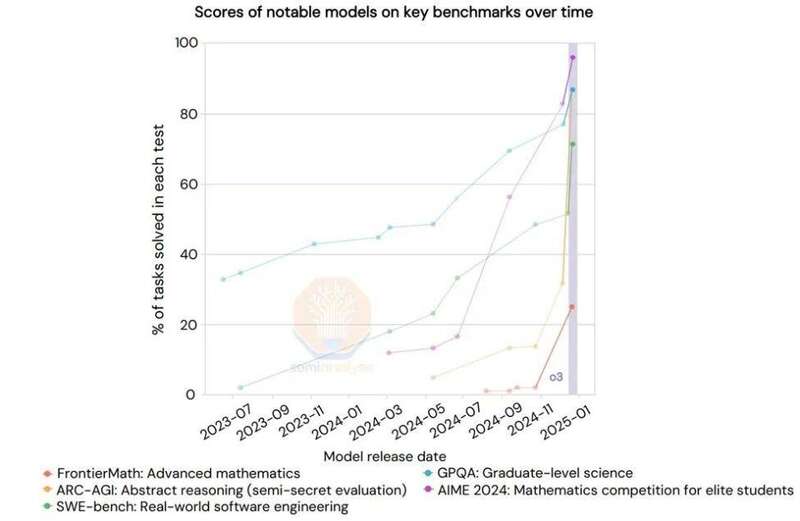
与 Google 的推理模型不相上下尽管 R1 的炒作热潮不断,但很多人忽略了,一家市值 2.5 万亿美元的美国公司在上个月以更低的价格发布了一款推理模型:Google 的 Gemini Flash 2.0 Thinking。
该模型已经可以使用,并且通过 API 即使拥有更长的上下文长度,其成本仍远低于 R1。
在已公布的基准测试中,Flash 2.0 Thinking 超越了 R1,尽管基准测试并不能说明全部情况。Google 只发布了 3 个基准测试,因此情况不够全面。不过,我们认为 Google 的模型非常稳健,在许多方面可以与 R1 相当,但却未获得太多关注。
这可能是由于 Google 营销策略平平、用户体验较差,但同时 R1 也作为一项来自中国的黑马出现。- 新闻来源于其它媒体,内容不代表本站立场!
- 问今天几月几号?DeepSeek回答笑翻网络
- DeepSeek走下坡路 传其核心高层悄然出走
- 加国工人被困熏制室 死因细思极恐
- 大温著名发廊 美发师都来自于日本
-
- 本周最低按揭利率 还选浮动要注意
- 坏消息接二连三,普京面临艰难抉择
- 加元延续本周跌势 预测再降息两次
- 胡春华突显上位节奏?胡锦涛之子高调揭牌露馅
- 一家4口每天吃自制馒头 都查出癌症 母亲后悔
- 顶级野模!年薪4300 万!秒杀肯豆,力压东契奇华子欧文!
-
- 非法移民扫荡仅一周后就立功!美国涌现这现象
- 阿拉伯世界看以伊冲突:不同情以色列,对伊....
- 决策小圈圈逐一被击毙 伊朗最高领袖误判局势
- 振龙电器 各类热销家电 种类齐全
- 蒙面人试图偷加国省长车 四人被捕
- 老朋友意外泄露习两个秘密 党媒急删
-
- ICBC预约太烦人 N牌司机不愿考5级
- 传齐心邀胡温等5元老赴家宴 规劝习8月底退位
- 继医疗危机后 BC教育系统陷入危机
- 他表态愿接党魁?中共权力核心正在变化
- 伊朗今晚准备了巨大惊喜?许多媒体可能误会了
- 勒索猖獗 尹大卫要定它为恐怖组织
-
目前还没有人发表评论, 大家都在期待您的高见
