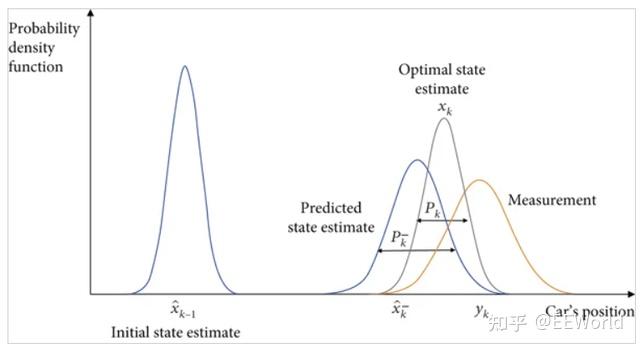
卡爾曼濾波器使用系統的動態模型(例如,運動的物理定律),該系統的已知控制輸入以及多個順序的測量值(例如來自傳感器的測量值)來形成對系統變化量(其狀態)更好的估計,其精度比僅使用一種測量獲得的估算值高。它是一種常見的
感測器融合和
數據融合算法。
感測器數據的雜訊,描述系統演化的方程式的近似值以及未考慮所有因素的外部因素都限制了確定系統狀態的能力。卡爾曼濾波器有效地處理了由於感測器數據雜訊引起的不確定性,並在一定程度上處理了隨機外部因素。卡爾曼濾波器使用
加權平均值生成系統狀態的估計值,作為系統預測狀態和新測量值的平均值。權重的目的是估計值具有更好(即較小)的不確定性的值會被更多“信任”。權重是根據
共變異數來計算的,共變異數是對系統狀態預測的估計不確定性的度量。加權平均值的結果是介於預測狀態和測量狀態之間的新狀態估計,並且比任何一個狀態都有更好的估計不確定性。在每個時間步重復此過程,新的估計值及其共變異數將通知後續迭代中使用的預測。這意味著卡爾曼濾波器可以
遞回地工作,並且只需要系統狀態的最後“最佳猜測”,而不是整個歷史,就可以計算新狀態。
測量和當前狀態估計的相對確定性是重要的考慮因素,通常根據卡爾曼濾波器的
增益來討論濾波器的反應。卡爾曼增益是賦予測量值和當前狀態估計值的相對權重,可以進行“調整”以獲得特定的性能。增益高時,濾波器將更多的精力放在最新的測量上,因此反應速度更快。增益較低時,濾波器會更緊密地遵循模型預測。在極端情況下,接近1的高增益將導致估計的軌跡更加跳躍,而接近零的低增益將消除雜訊,但會降低反應速度。
在執行濾波器的實際計算時(如下所述),狀態估計值和共變異數被編碼到
矩陣中,以處理單個計算集中涉及的多個維度。這允許在任何過渡模型或共變異數中表示不同狀態變量(例如位置,速度和加速度)之間的線性關系。
基本動態系統模型
卡爾曼濾波建立在
線性代數和
隱馬爾可夫模型(hidden Markov model)上。其基本動態系統可以用一個
馬爾可夫鏈表示,該馬爾可夫鏈建立在一個被高斯
噪聲(即正態分布的噪聲)幹擾的
線性算子上的。系統的
狀態可以用一個元素為實數的
向量表示。隨著
離散時間的每一個增加,這個線性算子就會作用在當前狀態上,產生一個新的狀態,並也會帶入一些噪聲,同時系統的一些已知的控制器的控制信息也會被加入。同時,另一個受噪聲幹擾的線性算子產生出這些隱含狀態的可見輸出。
為了從一系列有噪聲的觀察數據中用卡爾曼濾波器估計出被觀察過程的內部狀態,必須把這個過程在卡爾曼濾波的框架下建立模型。也就是說對於每一步
k,定義
矩陣Fk,
Hk,
Qk,
Rk,有時也需要定義
Bk,如下。
 卡爾曼濾波器的模型。圓圈代表向量,方塊代表矩陣,星號代表高斯噪聲,其協方差矩陣在右下方標出。
卡爾曼濾波器的模型。圓圈代表向量,方塊代表矩陣,星號代表高斯噪聲,其協方差矩陣在右下方標出。卡爾曼濾波模型假設k時刻的真實狀態是從(k − 1)時刻的狀態演化而來,符合下式:
xk=Fkxk−1+Bkuk+wk
其中
- Fk是作用在xk−1上的狀態變換模型(/矩陣/向量)。
- Bk是作用在控制器向量uk上的輸入-控制模型。
- wk是過程噪聲,並假定其符合均值為零,協方差矩陣為Qk的多元正態分布。
wk∼N(0,Qk)
時刻k,對真實狀態xk的一個測量zk滿足下式:
zk=Hkxk+vk
其中
Hk是觀測模型,它把真實狀態空間映射成觀測空間,
vk是觀測噪聲,其均值為零,協方差矩陣為
Rk,且服從
正態分布。

初始狀態以及每一時刻的噪聲{
x0,
w1, ...,
wk,
v1 ...
vk}都認為是互相
獨立的。
實際上,很多真實世界的動態系統都並不確切的符合這個模型;但是由於卡爾曼濾波器被設計在有噪聲的情況下工作,一個近似的符合已經可以使這個濾波器非常有用了。更多其它更復雜的卡爾曼濾波器的變種,在下邊討論中有描述。
卡爾曼濾波器
卡爾曼濾波是一種
遞歸的估計,即只要獲知上一時刻狀態的估計值以及當前狀態的觀測值就可以計算出當前狀態的估計值,因此不需要記錄觀測或者估計的歷史信息。卡爾曼濾波器與大多數濾波器不同之處,在於它是一種純粹的
時域濾波器,它不需要像
低通濾波器等
頻域濾波器那樣,需要在頻域設計再轉換到時域實現。
卡爾曼濾波器的狀態由以下兩個變量表示:
- x^k|k
 ,在時刻k的狀態的估計;
,在時刻k的狀態的估計; - Pk|k
 ,後驗估計誤差協方差矩陣,度量估計值的精確程度。
,後驗估計誤差協方差矩陣,度量估計值的精確程度。
卡爾曼濾波器的操作包括兩個階段:預測與更新。在預測階段,濾波器使用上一狀態的估計,做出對當前狀態的估計。在更新階段,濾波器利用對當前狀態的觀測值優化在預測階段獲得的預測值,以獲得一個更精確的新估計值。
預測
x^k|k−1=Fkx^k−1|k−1+Bkuk (預測狀態)Pk|k−1=FkPk−1|k−1FkT+Qk
(預測狀態)Pk|k−1=FkPk−1|k−1FkT+Qk (預測估計協方差矩陣)
(預測估計協方差矩陣)
更新
首先要算出以下三個量:
y~k=zk−Hkx^k|k−1 (測量殘差)Sk=HkPk|k−1HkT+Rk
(測量殘差)Sk=HkPk|k−1HkT+Rk (測量殘差協方差)Kk=Pk|k−1HkTSk−1
(測量殘差協方差)Kk=Pk|k−1HkTSk−1 (最優卡爾曼增益)
(最優卡爾曼增益)然後用它們來更新濾波器變量x與P:
x^k|k=x^k|k−1+Kky~k (更新的狀態估計)Pk|k=(I−KkHk)Pk|k−1
(更新的狀態估計)Pk|k=(I−KkHk)Pk|k−1 (更新的協方差估計)
(更新的協方差估計)使用上述公式計算Pk|k
僅在最優卡爾曼增益的時候有效。使用其他增益的話,公式要復雜一些,請參見
推導。
不變量(Invariant)
如果模型准確,而且x^0|0

與P0|0

的值准確的反映了最初狀態的分布,那麼以下不變量就保持不變:所有估計的誤差均值為零
- E[xk−x^k|k]=E[xk−x^k|k−1]=0

- E[y~k]=0

- Pk|k=cov(xk−x^k|k)

- Pk|k−1=cov(xk−x^k|k−1)

- Sk=cov(y~k)

請注意,其中E[a]

表示a

的期望值, cov(a)=E[aaT]

。
實例
考慮在無摩擦的、無限長的直軌道上的一輛車。該車最初停在位置0處,但時不時受到隨機的沖擊。每隔
Δt秒即測量車的位置,但是這個測量是非精確的;想建立一個關於其位置以及
速度的模型。來看如何推導出這個模型以及如何從這個模型得到卡爾曼濾波器。
因為車上無動力,所以可以忽略掉Bk和uk。由於F、H、R和Q是常數,所以時間下標可以去掉。
車的位置以及速度(或者更加一般的,一個粒子的運動狀態)可以被線性狀態空間描述如下:
xk=[xx˙]
其中x˙

是速度,也就是位置對於時間的導數。
假設在(
k − 1)時刻與
k時刻之間,車受到
ak的加速度,其符合均值為0,標准差為
σa的
正態分布。根據
牛頓運動定律,可以推出

其中
F=[1Δt01]
且
G=[Δt22Δt]
可以發現
Q=cov(Ga)=E[(Ga)(Ga)T]=GE[a2]GT=G[σa2]GT=σa2GGT (因為σa是一個標量)。
(因為σa是一個標量)。在每一時刻,對其位置進行測量,測量受到噪聲幹擾。假設噪聲服從正態分布,均值為0,標准差為σz。
zk=Hxk+vk
其中
H=[10]
且
R=E[vkvkT]=[σz2]
如果知道足夠精確的車最初的位置,那麼可以初始化
x^0|0=[00]
並且,若讓濾波器知道確切的初始位置,可給出一個協方差矩陣:
P0|0=[0000]
如果不確切的知道最初的位置與速度,那麼協方差矩陣可以初始化為一個對角線元素是B的矩陣,B取一個合適的比較大的數。
P0|0=[B00B]
此時,與使用模型中已有信息相比,濾波器更傾向於使用初次測量值的信息。
推導
推導後驗協方差矩陣
按照上邊的定義,從誤差協方差Pk|k
開始推導如下:
代入x^k|k

再代入 y~k


與zk


整理誤差向量,得
Pk|k=cov((I−KkHk)(xk−x^k|k−1)−Kkvk)
因為測量誤差vk與其他項是非相關的,因此有
Pk|k=cov((I−KkHk)(xk−x^k∣k−1))+cov(Kkvk) Pk|k=(I−KkHk)cov(xk−x^k|k−1)(I−KkHk)T+Kkcov(vk)KkT
Pk|k=(I−KkHk)cov(xk−x^k|k−1)(I−KkHk)T+Kkcov(vk)KkT
使用不變量Pk|k-1以及Rk的定義這一項可以寫作 :
Pk|k=(I−KkHk)Pk|k−1(I−KkHk)T+KkRkKkT

這一公式對於任何卡爾曼增益Kk都成立。如果Kk是最優卡爾曼增益,則可以進一步簡化,請見下文。
最優卡爾曼增益的推導
卡爾曼濾波器是
最小均方誤差估計器,後驗狀態誤差估計(英文:
a posteriori state estimate)是

最小化這個矢量幅度平方的期望值,E[|xk−x^k|k|2]

,這等同於最小化後驗估計協方差矩陣
Pk|
k的
跡(trace)。將上面方程中的項展開、抵消,得到:
 =Pk|k−1−KkHkPk|k−1−Pk|k−1HkTKkT+KkSkKkT
=Pk|k−1−KkHkPk|k−1−Pk|k−1HkTKkT+KkSkKkT
當
矩陣導數是0的時候得到
Pk|
k的
跡(trace)的最小值:

此處須用到一個常用的式子,如下:
dtr(BAC)dA=BTCT
從這個方程解出卡爾曼增益Kk:
KkSk=(HkPk|k−1)T=Pk|k−1HkT Kk=Pk|k−1HkTSk−1
Kk=Pk|k−1HkTSk−1
後驗誤差協方差公式的化簡
在卡爾曼增益等於上面導出的最優值時,計算後驗協方差的公式可以進行簡化。在卡爾曼增益公式兩側的右邊都乘以SkKkT得到
KkSkKkT=Pk|k−1HkTKkT
根據上面後驗誤差協方差展開公式,
Pk|k=Pk|k−1−KkHkPk|k−1−Pk|k−1HkTKkT+KkSkKkT
最後兩項可以抵消,得到
Pk|k=Pk|k−1−KkHkPk|k−1=(I−KkHk)Pk|k−1 .
.這個公式的計算比較簡單,所以實際中總是使用這個公式,但是需注意這公式僅在使用最優卡爾曼增益的時候它才成立。如果算術精度總是很低而導致
數值穩定性出現問題,或者特意使用非最優卡爾曼增益,那麼就不能使用這個簡化;必須使用上面導出的後驗誤差協方差公式。
與遞歸貝葉斯估計之間的關系
假設真正的狀態是無法觀察的
馬爾可夫過程,測量結果是從隱性馬爾可夫模型觀察到的狀態。
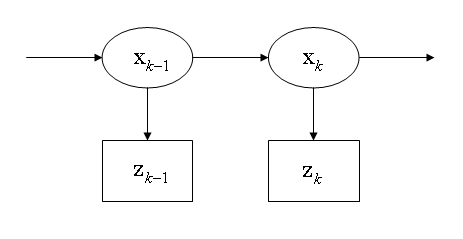
根據馬爾可夫假設,真正的狀態僅受最近一個狀態影響而與其它以前狀態無關。
p(xk|x0,…,xk−1)=p(xk|xk−1)
與此類似,在時刻k測量只與當前狀態有關而與其它狀態無關。
p(zk|x0,…,xk)=p(zk|xk)
根據這些假設,隱性馬爾可夫模型所有狀態的概率分布可以簡化為:
p(x0,…,xk,z1,…,zk)=p(x0)∏i=1kp(zi|xi)p(xi|xi−1)
然而,當卡爾曼濾波器用來估計狀態x時,感興趣的機率分布,是基於目前為止所有個測量值來得到的當前狀態之機率分布
p(xk|Zk−1)=∫p(xk|xk−1)p(xk−1|Zk−1)dxk−1
信息濾波器
在信息濾波器或逆共變異數濾波器中,估計的共變異數和估計狀態分別由
信息矩陣和
信息向量代替。 這些定義為:

同樣,預測的共變異數和狀態具有等效的信息形式,定義為:
Yk∣k−1=Pk∣k−1−1y^k∣k−1=Pk∣k−1−1x^k∣k−1
以及測量共變異數和測量向量,它們定義為:
Ik=HkTRk−1Hkik=HkTRk−1zk
信息更新現在變得微不足道了。
Yk∣k=Yk∣k−1+Iky^k∣k=y^k∣k−1+ik
信息過濾器的主要優點是,只需將其測量信息矩陣和向量相加即可在每個時間步長過濾N個測量值。
Yk∣k=Yk∣k−1+∑j=1NIk,jy^k∣k=y^k∣k−1+∑j=1Nik,j
為了預測信息過濾器,可以將信息矩陣和向量轉換回它們的狀態空間等效項,或者可以使用信息空間預測。
Mk=[Fk−1]TYk−1∣k−1Fk−1Ck=Mk[Mk+Qk−1]−1Lk=I−CkYk∣k−1=LkMkLkT+CkQk−1CkTy^k∣k−1=Lk[Fk−1]Ty^k−1∣k−1
如果F和Q是非時變的,則可以將這些值緩存起來,並且F和Q必須是可逆的。
頻率加權卡爾曼濾波器
在1930年代,Fletcher和Munson進行了有關不同頻率的聲音感知的開創性研究。他們的工作導致了在工業雜訊和聽力損失調查中加權測得的聲音水平的標准方法。此後,已在濾波器和控制器設計中使用了頻率 加權,以管理目標頻段內的性能。
通常,頻率整形函數用於加權指定頻段中誤差頻譜密度的平均功率。 令 y−y^

表示由 傳統的卡爾曼濾波器。 同樣,讓 W

表示因果頻率加權傳遞函數。 最小化 W(y−y^)

是通過簡單地構建 W−1y^

而產生的。
W
的設計仍然是一個懸而未決的問題。 一種進行方式是識別產生估計誤差的系統,並將 W
設置為等於該系統的倒數。 可以重復執行此過程,以提高均方誤差為代價,增加濾波器階數。可以將相同的技術應用於平滑器。














 論壇通告:
論壇通告:
 個人空間:
個人空間:

 論壇轉跳:
論壇轉跳:













 贊
贊  花籃
花籃  投訴
投訴 踩
踩  分享
分享