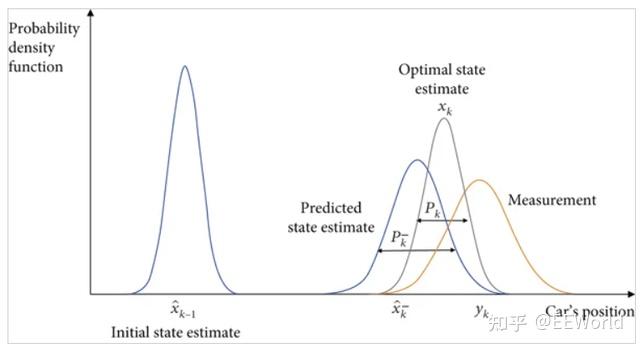
�������˲���ʹ��ϵͳ�Ķ�̬ģ�ͣ����磬�˶����������ɣ�����ϵͳ����֪���������Լ����˳��IJ���ֵ���������Դ������IJ���ֵ�����γɶ�ϵͳ�仯������״̬�����õĹ��ƣ��侫�ȱȽ�ʹ��һ�ֲ�����õĹ���ֵ�ߡ�����һ�ֳ�����
�в����ں���
�����ں��㷨��
�в������ݵ���Ѷ������ϵͳ�ݻ��ķ���ʽ�Ľ���ֵ�Լ�δ�����������ص��ⲿ���ض�������ȷ��ϵͳ״̬���������������˲�����Ч�ش��������ڸв���������Ѷ����IJ�ȷ���ԣ�����һ���̶��ϴ���������ⲿ���ء��������˲���ʹ��
��Ȩƽ��ֵ����ϵͳ״̬�Ĺ���ֵ����ΪϵͳԤ��״̬���²���ֵ��ƽ��ֵ��Ȩ�ص�Ŀ���ǹ���ֵ���и��ã�����С���IJ�ȷ���Ե�ֵ�ᱻ���ࡰ���Ρ���Ȩ���Ǹ���
��������������ģ����������Ƕ�ϵͳ״̬Ԥ��Ĺ��Ʋ�ȷ���ԵĶ�������Ȩƽ��ֵ�Ľ���ǽ���Ԥ��״̬�Ͳ���״̬֮�����״̬���ƣ����ұ��κ�һ��״̬���и��õĹ��Ʋ�ȷ���ԡ���ÿ��ʱ�䲽�ظ��˹��̣��µĹ���ֵ���乲��������֪ͨ����������ʹ�õ�Ԥ�⡣����ζ���������˲�������
�ݻ��ع���������ֻ��Ҫϵͳ״̬�������Ѳ²⡱��������������ʷ���Ϳ��Լ�����״̬��
�����͵�ǰ״̬���Ƶ����ȷ��������Ҫ�Ŀ������أ�ͨ�����ݿ������˲�����
�����������˲����ķ�Ӧ�������������Ǹ������ֵ�͵�ǰ״̬����ֵ�����Ȩ�أ����Խ��С��������Ի���ض������ܡ������ʱ���˲���������ľ����������µIJ����ϣ���˷�Ӧ�ٶȸ��졣����ϵ�ʱ���˲���������ܵ���ѭģ��Ԥ�⡣�ڼ�������£��ӽ�1�ĸ����潫���¹��ƵĹ켣������Ծ�����ӽ���ĵ����潫������Ѷ�����ή�ͷ�Ӧ�ٶȡ�
��ִ���˲�����ʵ�ʼ���ʱ��������������״̬����ֵ�������������뵽
�����У��Դ����������㼯���漰�Ķ��ά�ȡ����������κι���ģ�ͻ������б�ʾ��ͬ״̬����������λ�ã��ٶȺͼ��ٶȣ�֮������Թ�ϵ��
������̬ϵͳģ��
�������˲�������
���Դ�����
�������ɷ�ģ����hidden Markov model���ϡ��������̬ϵͳ������һ��
�����ɷ�����ʾ���������ɷ���������һ������˹
����������̬�ֲ������������ŵ�
���������ϵġ�ϵͳ��
״̬������һ��Ԫ��Ϊʵ����
������ʾ������
��ɢʱ����ÿһ�����ӣ�����������Ӿͻ������ڵ�ǰ״̬�ϣ�����һ���µ�״̬����Ҳ�����һЩ������ͬʱϵͳ��һЩ��֪�Ŀ������Ŀ�����ϢҲ�ᱻ���롣ͬʱ����һ�����������ŵ��������Ӳ�������Щ����״̬�Ŀɼ������
Ϊ�˴�һϵ���������Ĺ۲��������ÿ������˲������Ƴ����۲���̵��ڲ�״̬���������������ڿ������˲��Ŀ���½���ģ�͡�Ҳ����˵����ÿһ��
k������
����Fk,
Hk,
Qk,
Rk����ʱҲ��Ҫ����
Bk�����¡�
 �������˲�����ģ�͡�ԲȦ������������������������ǺŴ�����˹��������Э������������·������
�������˲�����ģ�͡�ԲȦ������������������������ǺŴ�����˹��������Э������������·�������������˲�ģ�ͼ���kʱ�̵���ʵ״̬�Ǵӣ�k − 1��ʱ�̵�״̬�ݻ�������������ʽ��
xk=Fkxk−1+Bkuk+wk
����
- Fk��������xk−1�ϵ�״̬�任ģ�ͣ�/����/��������
- Bk�������ڿ���������uk�ϵ����룭����ģ�͡�
- wk�ǹ������������ٶ�����Ͼ�ֵΪ�㣬Э�������ΪQk����Ԫ��̬�ֲ���
wk∼N(0,Qk)
ʱ��k������ʵ״̬xk��һ������zk������ʽ��
zk=Hkxk+vk
����
Hk�ǹ۲�ģ�ͣ�������ʵ״̬�ռ�ӳ��ɹ۲�ռ䣬
vk�ǹ۲����������ֵΪ�㣬Э�������Ϊ
Rk,�ҷ���
��̬�ֲ���

��ʼ״̬�Լ�ÿһʱ�̵�����{
x0,
w1, ...,
wk,
v1 ...
vk}����Ϊ�ǻ���
�����ġ�
ʵ���ϣ��ܶ���ʵ����Ķ�̬ϵͳ������ȷ�еķ������ģ�ͣ��������ڿ������˲����������������������¹�����һ�����Ƶķ����Ѿ�����ʹ����˲����dz������ˡ��������������ӵĿ������˲����ı��֣����±���������������
�������˲���
�������˲���һ��
�ݹ��Ĺ��ƣ���ֻҪ��֪��һʱ��״̬�Ĺ���ֵ�Լ���ǰ״̬�Ĺ۲�ֵ�Ϳ��Լ������ǰ״̬�Ĺ���ֵ����˲���Ҫ��¼�۲���߹��Ƶ���ʷ��Ϣ���������˲����������˲�����֮ͬ������������һ�ִ����
ʱ���˲�����������Ҫ��
��ͨ�˲�����
Ƶ���˲�����������Ҫ��Ƶ�������ת����ʱ��ʵ�֡�
�������˲�����״̬����������������ʾ��
- x^k|k
 ����ʱ��k��״̬�Ĺ��ƣ�
����ʱ��k��״̬�Ĺ��ƣ� - Pk|k
 ������������Э�����������������ֵ�ľ�ȷ�̶ȡ�
������������Э�����������������ֵ�ľ�ȷ�̶ȡ�
�������˲����IJ������������Σ�Ԥ������������Ԥ��Σ��˲���ʹ����һ״̬�Ĺ��ƣ������Ե�ǰ״̬�Ĺ��ơ��ڸ��½Σ��˲������öԵ�ǰ״̬�Ĺ۲�ֵ�Ż���Ԥ��λ�õ�Ԥ��ֵ���Ի��һ������ȷ���¹���ֵ��
Ԥ��
x^k|k−1=Fkx^k−1|k−1+Bkuk ��Ԥ��״̬��Pk|k−1=FkPk−1|k−1FkT+Qk
��Ԥ��״̬��Pk|k−1=FkPk−1|k−1FkT+Qk ��Ԥ�����Э�������
��Ԥ�����Э�������
����
����Ҫ���������������
y~k=zk−Hkx^k|k−1 �������вSk=HkPk|k−1HkT+Rk
�������вSk=HkPk|k−1HkT+Rk �������в�Э���Kk=Pk|k−1HkTSk−1
�������в�Э���Kk=Pk|k−1HkTSk−1 �����ſ��������棩
�����ſ��������棩Ȼ���������������˲�������x��P��
x^k|k=x^k|k−1+Kky~k �����µ�״̬���ƣ�Pk|k=(I−KkHk)Pk|k−1
�����µ�״̬���ƣ�Pk|k=(I−KkHk)Pk|k−1 �����µ�Э������ƣ�
�����µ�Э������ƣ�ʹ��������ʽ����Pk|k
�������ſ����������ʱ����Ч��ʹ����������Ļ�����ʽҪ����һЩ����μ�
�Ƶ���
��������Invariant��
���ģ��ȷ������x^0|0

��P0|0

��ֵȷ�ķ�ӳ�����״̬�ķֲ�����ô���²������ͱ��ֲ��䣺���й��Ƶ�����ֵΪ��
- E[xk−x^k|k]=E[xk−x^k|k−1]=0

- E[y~k]=0

- Pk|k=cov(xk−x^k|k)

- Pk|k−1=cov(xk−x^k|k−1)

- Sk=cov(y~k)

��ע�⣬����E[a]

��ʾa

������ֵ, cov(a)=E[aaT]

��
ʵ��
��������Ħ���ġ�������ֱ����ϵ�һ�������ó����ͣ��λ��0������ʱ��ʱ�ܵ�����ij����ÿ��
��t�뼴��������λ�ã�������������ǷǾ�ȷ�ģ��뽨��һ��������λ���Լ�
�ٶ���ģ�͡���������Ƶ������ģ���Լ���δ����ģ�͵õ��������˲�����
��Ϊ�������������Կ��Ժ��Ե�Bk��uk������F��H��R��Q�dz���������ʱ���±����ȥ����
����λ���Լ��ٶȣ����߸���һ��ģ�һ�����ӵ��˶�״̬�����Ա�����״̬�ռ��������£�
xk=[xx�B]
����x�B

���ٶȣ�Ҳ����λ�ö���ʱ��ĵ�����
�����ڣ�
k − 1��ʱ����
kʱ��֮�䣬���ܵ�
ak�ļ��ٶȣ�����Ͼ�ֵΪ0������Ϊ
��a��
��̬�ֲ�������
ţ���˶������������Ƴ�

����
F=[1��t01]
��
G=[��t22��t]
���Է���
Q=cov(Ga)=E[(Ga)(Ga)T]=GE[a2]GT=G[��a2]GT=��a2GGT ����Ϊ��a��һ����������
����Ϊ��a��һ������������ÿһʱ�̣�����λ�ý��в����������ܵ��������š���������������̬�ֲ�����ֵΪ0������Ϊ��z��
zk=Hxk+vk
����
H=[10]
��
R=E[vkvkT]=[��z2]
���֪���㹻��ȷ�ij������λ�ã���ô���Գ�ʼ��
x^0|0=[00]
���ң������˲���֪��ȷ�еij�ʼλ�ã��ɸ���һ��Э�������
P0|0=[0000]
�����ȷ�е�֪�������λ�����ٶȣ���ôЭ���������Գ�ʼ��Ϊһ���Խ���Ԫ����B�ľ���Bȡһ�����ʵıȽϴ������
P0|0=[B00B]
��ʱ����ʹ��ģ����������Ϣ��ȣ��˲�����������ʹ�ó��β���ֵ����Ϣ��
�Ƶ�
�Ƶ�����Э�������
�����ϱߵĶ��壬�����Э����Pk|k
��ʼ�Ƶ����£�
����x^k|k

�ٴ��� y~k


��zk


���������������
Pk|k=cov((I−KkHk)(xk−x^k|k−1)−Kkvk)
��Ϊ�������vk���������Ƿ���صģ������
Pk|k=cov((I−KkHk)(xk−x^k�Ok−1))+cov(Kkvk) Pk|k=(I−KkHk)cov(xk−x^k|k−1)(I−KkHk)T+Kkcov(vk)KkT
Pk|k=(I−KkHk)cov(xk−x^k|k−1)(I−KkHk)T+Kkcov(vk)KkT
ʹ�ò�����Pk|k-1�Լ�Rk�Ķ�����һ�����д�� ��
Pk|k=(I−KkHk)Pk|k−1(I−KkHk)T+KkRkKkT

��һ��ʽ�����κο���������Kk�����������Kk�����ſ��������棬����Խ�һ����������ġ�
���ſ�����������Ƶ�
�������˲�����
��С�������������������״̬�����ƣ�Ӣ�ģ�
a posteriori state estimate����

��С�����ʸ������ƽ��������ֵ��E[|xk−x^k|k|2]

�����ͬ����С���������Э�������
Pk|
k��
����trace���������淽���е���չ�����������õ���
 =Pk|k−1−KkHkPk|k−1−Pk|k−1HkTKkT+KkSkKkT
=Pk|k−1−KkHkPk|k−1−Pk|k−1HkTKkT+KkSkKkT
��
��������0��ʱ��õ�
Pk|
k��
����trace������Сֵ��

�˴����õ�һ�����õ�ʽ�ӣ����£�
dtr(BAC)dA=BTCT
��������̽������������Kk��
KkSk=(HkPk|k−1)T=Pk|k−1HkT Kk=Pk|k−1HkTSk−1
Kk=Pk|k−1HkTSk−1
�������Э���ʽ�Ļ���
�ڿ���������������浼��������ֵʱ���������Э����Ĺ�ʽ���Խ��м��ڿ��������湫ʽ������ұ߶�����SkKkT�õ�
KkSkKkT=Pk|k−1HkTKkT
��������������Э����չ����ʽ��
Pk|k=Pk|k−1−KkHkPk|k−1−Pk|k−1HkTKkT+KkSkKkT
���������Ե������õ�
Pk|k=Pk|k−1−KkHkPk|k−1=(I−KkHk)Pk|k−1 .
.�����ʽ�ļ���Ƚϼ�����ʵ��������ʹ�������ʽ��������ע���ʽ����ʹ�����ſ����������ʱ�����ų�������������������ǺܵͶ�����
��ֵ�ȶ����������⣬��������ʹ�÷����ſ��������棬��ô�Ͳ���ʹ�����������ʹ�����浼���ĺ������Э���ʽ��
��ݹ鱴Ҷ˹����֮��Ĺ�ϵ
����������״̬�����۲��
�����ɷ��������������Ǵ����������ɷ�ģ�۲쵽��״̬��
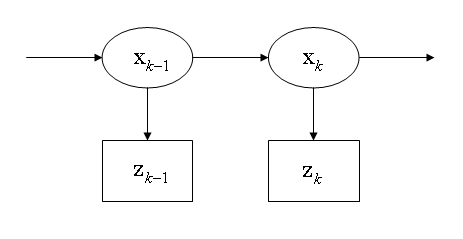
���������ɷ���裬������״̬�������һ��״̬Ӱ�����������ǰ״̬�ء�
p(xk|x0,��,xk−1)=p(xk|xk−1)
������ƣ���ʱ��k����ֻ�뵱ǰ״̬�йض�������״̬�ء�
p(zk|x0,��,xk)=p(zk|xk)
������Щ���裬���������ɷ�ģ������״̬�ĸ��ʷֲ����Լ�Ϊ��
p(x0,��,xk,z1,��,zk)=p(x0)��i=1kp(zi|xi)p(xi|xi−1)
Ȼ�������������˲�����������״̬xʱ������Ȥ�Ļ��ʷֲ����ǻ���ĿǰΪֹ���и�����ֵ���õ��ĵ�ǰ״̬֮���ʷֲ�
p(xk|Zk−1)=��p(xk|xk−1)p(xk−1|Zk−1)dxk−1
��Ϣ�˲���
����Ϣ�˲������湲�������˲����У����ƵĹ�����������״̬�ֱ���
��Ϣ������
��Ϣ�������档 ��Щ����Ϊ��

ͬ����Ԥ��Ĺ���������״̬���е�Ч����Ϣ��ʽ������Ϊ��
Yk�Ok−1=Pk�Ok−1−1y^k�Ok−1=Pk�Ok−1−1x^k�Ok−1
�Լ��������������Ͳ������������Ƕ���Ϊ��
Ik=HkTRk−1Hkik=HkTRk−1zk
��Ϣ�������ڱ��������ˡ�
Yk�Ok=Yk�Ok−1+Iky^k�Ok=y^k�Ok−1+ik
��Ϣ����������Ҫ�ŵ��ǣ�ֻ�轫�������Ϣ�����������Ӽ�����ÿ��ʱ�䲽������N������ֵ��
Yk�Ok=Yk�Ok−1+��j=1NIk,jy^k�Ok=y^k�Ok−1+��j=1Nik,j
Ϊ��Ԥ����Ϣ�����������Խ���Ϣ���������ת�������ǵ�״̬�ռ��Ч����߿���ʹ����Ϣ�ռ�Ԥ�⡣
Mk=[Fk−1]TYk−1�Ok−1Fk−1Ck=Mk[Mk+Qk−1]−1Lk=I−CkYk�Ok−1=LkMkLkT+CkQk−1CkTy^k�Ok−1=Lk[Fk−1]Ty^k−1�Ok−1
���F��Q�Ƿ�ʱ��ģ�����Խ���Щֵ��������������F��Q�����ǿ���ġ�
Ƶ�ʼ�Ȩ�������˲���
��1930�����Fletcher��Munson�������йز�ͬƵ�ʵ�������֪�Ŀ������о������ǵĹ����������ڹ�ҵ��Ѷ��������ʧ�����м�Ȩ��õ�����ˮƽ�ı��������˺������˲����Ϳ����������ʹ����Ƶ�� ��Ȩ���Թ���Ŀ��Ƶ���ڵ����ܡ�
ͨ����Ƶ�����κ������ڼ�Ȩָ��Ƶ�������Ƶ���ܶȵ�ƽ�����ʡ� �� y−y^

��ʾ�� ��ͳ�Ŀ������˲����� ͬ������ W

��ʾ���Ƶ�ʼ�Ȩ���ݺ����� ��С�� W(y−y^)

��ͨ���ع��� W−1y^

�������ġ�
W
�������Ȼ��һ������δ�������⡣ һ�ֽ��з�ʽ��ʶ�������������ϵͳ������ W
����Ϊ���ڸ�ϵͳ�ĵ����� �����ظ�ִ�д˹��̣�����߾������Ϊ���ۣ������˲������������Խ���ͬ�ļ���Ӧ����ƽ������














 Global Announcement:
Global Announcement:
 :
:

 Jump to:
Jump to: